The Complete Guide to AI-Based OCR Development Services

AI-based OCR development services are enabling enterprises to automate document-heavy workflows that were once entirely manual. By converting unstructured data from invoices, contracts, medical records, and logistics documents into structured, machine-readable information, custom AI OCR technology eliminates manual data entry, reduces processing errors, and unlocks operational efficiency at scale. This complete guide covers what AI-based OCR is, how it differs from traditional OCR, the core technologies involved, key enterprise benefits, industry use cases across finance, healthcare and logistics, the development process, and what to look for when choosing an AI OCR development partner.
Key Takeaways
- AI-based OCR uses deep learning and NLP to achieve accuracy rates of 95 to 99 percent, far exceeding traditional rule-based OCR systems limited to structured document formats
- Custom AI OCR development delivers solutions tailored to specific document types, industry workflows, and integration requirements across ERP, CRM, and cloud platforms
- IdeaGCS builds enterprise-grade AI OCR solutions for clients in the UK, India, US, UAE, and Philippines across finance, healthcare, logistics, and legal sectors
What Is AI-Based OCR and How Does It Work?
AI-based OCR, or artificial intelligence optical character recognition, is a technology that uses machine learning models to read, interpret, and extract data from documents. Unlike traditional OCR systems that rely on fixed templates and rule-based pattern matching, AI OCR uses neural networks trained on large datasets of real-world documents to understand text in context, regardless of layout variations, font differences, handwriting styles, or image quality. The result is a system that can process invoices, contracts, medical records, and logistics documents with a level of accuracy and flexibility that traditional OCR systems simply cannot achieve.
AI OCR systems work through a multi-stage pipeline. The document is first pre-processed to improve image quality through noise reduction, deskewing, and contrast normalisation. A detection model then identifies regions of text within the document. A recognition model reads the text within each identified region, applying contextual understanding to resolve ambiguous characters. Finally, a post-processing layer structures the extracted data into the format required by the downstream system, whether that is an ERP, a database, or a cloud storage platform.
How AI OCR Differs from Simple Image-to-Text Conversion
Basic image-to-text conversion tools extract whatever text they can detect in a document without understanding context, structure, or data relationships. AI-based OCR development goes considerably further. A well-trained AI OCR model understands that the number below the words 'Invoice Total' is a financial figure requiring a specific format, that a date field should be normalised to a consistent standard, and that a signature block does not need to be extracted as text. This contextual intelligence is what transforms raw text extraction into structured, actionable data that business systems can consume directly.
The Role of Training Data in AI OCR Accuracy
The accuracy of an AI OCR solution is directly determined by the quality and diversity of the training data used to build it. A model trained on a narrow dataset will perform well on documents similar to those it was trained on but will degrade significantly when presented with variations in layout, font, or language. IdeaGCS invests heavily in training data curation as part of every AI OCR development engagement, working with clients to gather representative samples of every document variant the solution will encounter in production before a single line of model code is written.
Traditional OCR vs AI OCR: Key Differences
Understanding the differences between traditional and AI-based OCR is essential for any organisation evaluating document automation technology. The gap between the two approaches is not merely technical. It translates directly into business outcomes: accuracy rates, processing speed, integration complexity, and the range of document types a system can handle reliably. Organisations that have invested in traditional OCR systems and are experiencing persistent accuracy problems, high exception rates, or significant manual correction workflows are typically encountering the fundamental limitations of rule-based optical character recognition.

[Alt: Comparison infographic showing traditional OCR versus AI-based OCR development across eight key performance dimensions] | File: infographic-1-traditional-ocr-vs-ai-ocr.png
Limitations of Traditional OCR Systems
Traditional OCR systems were designed for structured, predictable documents: printed forms with consistent layouts, fonts, and field positions. They work adequately in highly controlled environments where every document follows a known template. The moment documents deviate from that template, accuracy drops sharply. A single pixel of rotation, a slightly different font size, a handwritten annotation in the margin, or a non-standard invoice layout from a new supplier can cause a traditional OCR system to fail entirely or produce output requiring significant manual correction. For enterprises processing large volumes of documents from multiple sources, this brittleness makes traditional OCR an inadequate solution.
What AI Changes for Optical Character Recognition
AI-based OCR systems are trained to handle variability rather than avoid it. A well-trained model processes handwritten text, degraded scan quality, multi-column layouts, and mixed-language documents without requiring template updates or manual configuration. Accuracy rates of 95 to 99 percent are achievable across diverse document populations, compared to the 70 to 85 percent typical of traditional OCR on structured documents only. For enterprises processing invoices from hundreds of different suppliers, medical records from multiple facilities, or logistics documents from international partners, this accuracy advantage translates directly into fewer exceptions, less manual review, and lower processing costs. Explore our detailed analysis of AI OCR automation tools to understand how AI OCR performs across real enterprise document workflows.
Core Technologies Powering AI OCR Development
Building a high-performance AI OCR solution requires the integration of several machine learning disciplines working together within a coherent architecture. No single technology delivers the full capability that enterprise document automation demands. The combination of computer vision, deep learning, and natural language processing, applied within a purpose-built pipeline, is what separates a production-grade AI OCR system from a basic text extraction tool. Understanding these technologies helps organisations evaluate the technical credibility of any AI OCR development partner they are considering.
Deep Learning and Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are the foundational technology in modern AI OCR development. CNNs learn to identify visual features in document images through layers of pattern detection, progressively building from low-level features like edges and curves to high-level recognition of characters, words, and document structures. Modern AI OCR systems also leverage transformer architectures, which apply attention mechanisms to understand the contextual relationships between text elements across the full document. This combination of CNN-based visual processing and transformer-based contextual understanding delivers accuracy levels that were simply not achievable with earlier machine learning approaches.
Natural Language Processing and Computer Vision
Natural language processing adds a layer of semantic understanding to the raw text output of the visual recognition model. NLP components validate extracted data against expected formats, resolve ambiguous readings using contextual probability, normalise dates, currencies, and identifiers to consistent standards, and classify extracted fields by their semantic role within the document. Computer vision techniques handle the pre-processing stage, correcting image quality issues that would otherwise reduce recognition accuracy. Together, these technologies form the multi-layer pipeline that gives AI OCR its characteristic robustness across real-world document populations. The NIST AI standards programme provides a useful reference framework for evaluating AI OCR model trustworthiness, accuracy benchmarks, and responsible deployment practices in regulated environments. For a practical view of how these capabilities apply in enterprise workflows, see our guide to AI OCR use cases across industries.
Key Benefits of AI-Based OCR for Enterprises
The business case for AI-based OCR development is grounded in measurable improvements to operational efficiency, data accuracy, and processing cost. Organisations that have deployed custom AI OCR solutions consistently report significant reductions in document processing time, lower error rates, reduced dependency on manual data entry headcount, and faster downstream business processes that rely on the extracted data. These benefits compound over time as the AI model continues to improve through exposure to production document volumes.
Speed, Accuracy, and Cost Reduction
AI OCR systems process documents in seconds rather than the minutes or hours required for manual data entry. A finance team processing 10,000 invoices per month manually at an average of five minutes per invoice spends over 800 person-hours on a single workflow. An AI OCR solution with 98 percent straight-through processing reduces that effort to exception handling only, freeing skilled staff for higher-value activities. According to McKinsey research on AI adoption, organisations that automate document-intensive workflows report processing cost reductions of 40 to 60 percent alongside significant improvements in data quality and audit trail completeness.
Scalability, Compliance, and Audit Readiness
Manual document processing does not scale. As business volume grows, headcount must grow proportionally to maintain throughput and accuracy. An AI OCR system scales horizontally to handle any volume of documents without additional staffing cost, processing peak volumes as efficiently as baseline volumes. From a compliance perspective, AI OCR creates a complete, timestamped audit trail for every document processed, capturing the extracted data, the confidence score for each field, and any exceptions raised. This audit trail is increasingly valuable for organisations operating under regulatory frameworks in finance, healthcare, and legal services that require documented evidence of data processing decisions.
AI OCR as the Foundation of Intelligent Document Processing
According to Gartner's analysis of intelligent document processing, organisations that deploy AI-driven document processing solutions reduce manual review effort by up to 70 percent and achieve return on investment within the first 12 months. AI OCR is the foundational layer of an intelligent document processing strategy, providing the accurate structured data that powers downstream automation of approvals, three-way matching, exception routing, and workflow triggers. Organisations that deploy AI OCR as a standalone capability achieve significant efficiency gains. Those that integrate it within a broader document automation architecture achieve transformative reductions in end-to-end processing costs, cycle times, and dependency on manual intervention at every stage of the document lifecycle.
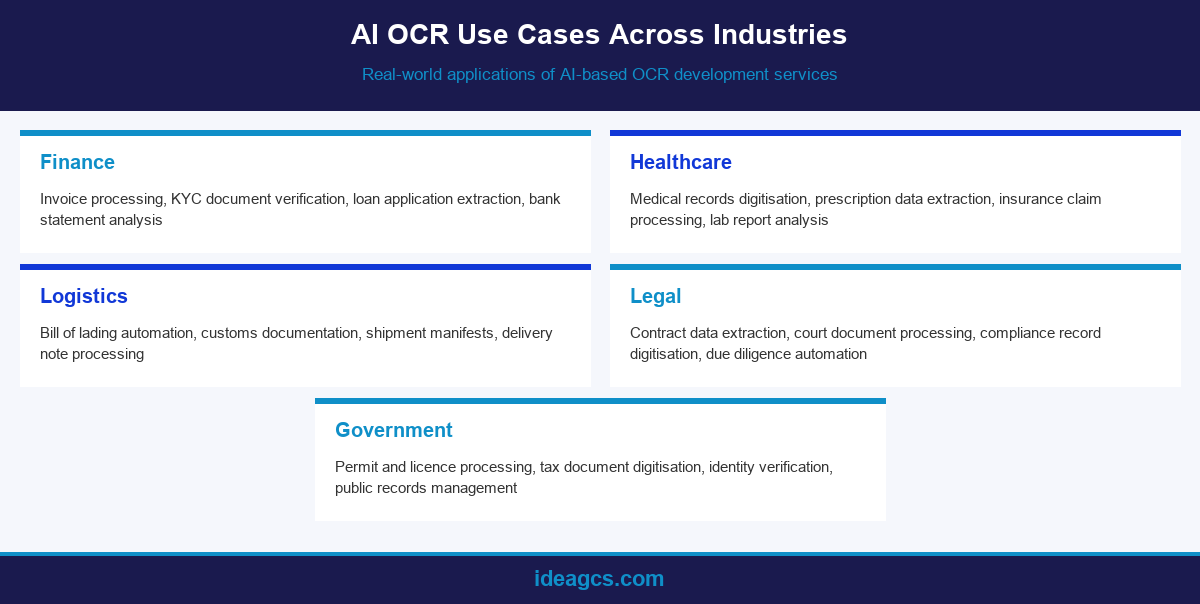
AI OCR Use Cases Across Industries
AI-based OCR development services are deployed across a wide range of industries, each with distinct document types, accuracy requirements, and integration environments. The common thread is the need to extract structured data from high volumes of varied documents reliably and efficiently. The following industry applications represent the most common and highest-value use cases that IdeaGCS addresses through custom AI OCR development engagements.

[Alt: Infographic showing AI OCR use cases across finance, healthcare, logistics, legal, and government sectors] | File: infographic-3-ai-ocr-industry-use-cases.png
Finance, Healthcare, and Logistics
In finance, AI OCR automates invoice processing, purchase order matching, bank statement analysis, KYC document verification, and loan application data extraction. These workflows are characterised by high volume, strict accuracy requirements, and direct financial consequences for errors. Healthcare organisations use AI OCR to digitise medical records, extract prescription data, process insurance claims, and manage lab reports, with accuracy and privacy compliance being paramount. In logistics, AI OCR automates the extraction of data from bills of lading, customs documentation, shipment manifests, and delivery notes, enabling real-time visibility into supply chain status without manual data entry at each stage.
Legal, Government, and Cross-Sector Applications
Legal firms and corporate legal departments use AI OCR to extract key clauses and dates from contracts, digitise court documents, automate compliance record processing, and accelerate due diligence workflows. Government agencies deploy AI OCR for permit and licence processing, tax document digitisation, identity verification, and public records management. Beyond these sector-specific applications, AI OCR is increasingly used in cross-sector contexts such as accounts payable automation, vendor onboarding, and employee records management, where the underlying challenge of extracting structured data from varied document formats is consistent regardless of industry.
How AI OCR Development Works: The Build Process
Developing a production-grade AI OCR solution is a structured engineering process that requires expertise across machine learning, computer vision, software architecture, and integration design. Organisations considering custom AI OCR development should understand the key phases of this process to set realistic expectations for timelines, data requirements, and testing effort. A well-managed AI OCR development engagement follows six core phases, each building on the outputs of the previous phase to deliver a solution that performs reliably in production from day one.
[Alt: Infographic showing the six-phase AI OCR development process from requirements through to deployment and monitoring] | File: infographic-2-ai-ocr-development-process.png
Requirements, Data Collection, and Model Training
The engagement begins with a detailed requirements phase covering document types, target data fields, accuracy thresholds, throughput requirements, and integration endpoints. IdeaGCS then works with the client to collect and annotate a representative training dataset covering all document variants the solution will encounter. This dataset is the foundation of model accuracy: no amount of algorithmic sophistication can compensate for a training dataset that does not reflect the real-world document population. Model training follows, with iterative validation cycles to verify that accuracy targets are being met across the full range of document types before any integration work begins.
API Development, Integration, and Deployment
Once the model meets accuracy requirements, the development team builds the API layer that exposes the OCR capability to downstream systems. This typically involves a REST API that accepts document inputs in common formats (PDF, TIFF, JPEG, PNG), returns structured JSON output containing extracted field values and confidence scores, and handles exception flagging for documents requiring human review. Integration with the client's ERP, CRM, or document management system is then completed and tested end-to-end before production deployment. IdeaGCS supports both cloud-native deployment on AWS, Azure, or GCP and on-premise deployment for clients with data residency requirements.
Integrating AI OCR with ERPs, CRMs, and Cloud Platforms
The value of an AI OCR solution is fully realised only when it is deeply integrated with the downstream systems that consume the extracted data. A standalone OCR tool that requires manual copy-paste of results into an ERP or CRM system adds process steps rather than eliminating them. True document automation requires the AI OCR system to deliver structured data directly to the target system through a reliable, monitored integration layer that handles exceptions, validates data quality, and maintains a complete audit trail of every transaction.
ERP and CRM Integration Patterns
IdeaGCS AI OCR solutions are designed API-first to integrate with leading ERP platforms including SAP, Oracle, Microsoft Dynamics, and NetSuite, as well as CRM systems such as Salesforce and HubSpot. Integration is typically achieved through REST API calls that trigger document processing on upload, with the structured output posted directly to the target system's data model. For invoice processing integrations, this means extracted header data (vendor, date, total), line item data (description, quantity, unit price), and tax information are mapped to the corresponding ERP fields and posted for automated three-way matching against purchase orders and goods receipts. Our team of digital transformation engineers manages the full integration design and testing process.
Cloud-Native and On-Premise Deployment
Cloud-native AI OCR deployment on platforms such as AWS Textract, Google Document AI, or Azure Form Recogniser provides scalability and managed infrastructure at the cost of some customisation flexibility. Custom model development, as delivered by IdeaGCS, provides significantly higher accuracy on domain-specific documents but requires a deployment environment that can host the trained model and serve inference requests at the required throughput. IdeaGCS supports both deployment models, selecting the architecture that best fits the client's infrastructure preferences, data residency requirements, and long-term operational cost profile.
IdeaGCS AI OCR Development Services
IdeaGCS delivers end-to-end AI-based OCR development services for enterprises across the UK, India, US, UAE, and Philippines. Our team combines expertise in deep learning, computer vision, NLP, and enterprise software integration to build AI OCR solutions that perform reliably in production environments, integrate seamlessly with existing business systems, and improve continuously through ongoing model monitoring and retraining. Every engagement begins with a thorough requirements and data analysis phase to ensure the solution we build is precisely calibrated to the client's document population and accuracy requirements.
Every IdeaGCS AI OCR engagement is scoped around the client's specific document population, not a generic template. We begin by cataloguing the full range of document types the solution must handle, identifying the data fields that need to be extracted from each, and establishing the accuracy benchmarks that will govern model acceptance. This document-first approach ensures that the solution we build is calibrated to the real-world variability clients encounter in production, rather than optimised only for the clean, well-formatted samples that make demo performance look impressive but fail to reflect operational reality.
Our AI OCR Development Approach
IdeaGCS follows a structured six-phase development methodology covering requirements definition, data collection and annotation, model training and validation, API development, system integration, and production deployment with monitoring. We work collaboratively with the client's technical and business teams throughout each phase, providing regular accuracy benchmarks, integration test results, and deployment readiness assessments. Our solutions are built to be maintainable: we deliver full documentation, model versioning, and retraining pipelines so clients can continue to improve accuracy as their document populations evolve. Learn more about IdeaGCS and our full portfolio of AI and data engineering capabilities.
Why Choose IdeaGCS for AI OCR Development
Organisations that partner with IdeaGCS for AI OCR development gain a team with genuine expertise across every layer of the technology stack, from model architecture and training data strategy through to production deployment and ongoing monitoring. We have delivered AI OCR solutions across finance, healthcare, logistics, and legal sectors, with accuracy rates consistently exceeding 97 percent on client document populations. Our five-market reach means we can support clients with multi-geography document processing requirements, including multi-language OCR and market-specific compliance considerations. To discuss your AI OCR development requirements, contact IdeaGCS today and we will arrange a technical discovery session with our AI engineering team.
Conclusion
AI-based OCR development services represent one of the highest-return technology investments available to document-intensive enterprises. The combination of deep learning accuracy, NLP-driven data structuring, and seamless ERP and CRM integration eliminates manual data entry workflows, reduces processing errors, and creates a scalable, audit-ready document automation capability that grows with the business. IdeaGCS brings the technical depth and delivery experience to make this transformation a reality for enterprises across the UK, India, US, UAE, and Philippines. Explore our AI and data services or contact our team today to begin your AI OCR development journey.
Frequently Asked Questions
What is AI-based OCR development?
How accurate is AI OCR compared to traditional OCR?
What types of documents can AI OCR process?
How long does AI OCR development take?
What systems can AI OCR integrate with?
What is the cost of custom AI OCR development?
Can AI OCR handle handwritten documents?
How does AI OCR handle multiple languages?
Is AI OCR suitable for regulated industries like healthcare and finance?
How do I get started with AI OCR development?
Contact Us
Share on Social Media
Contact Us